Deploying Contextual Bandits: Production Guide and Offline Evaluation
Part 5 of 5: From Research to Production
TL;DR: Deploying contextual bandits requires more than implementing an algorithm. You need offline evaluation (to validate before going live), production architecture (8 core components), comprehensive logging, monitoring dashboards, safety mechanisms, and a phased deployment strategy. This post provides the complete production playbook with checklists, code, and architecture patterns used at scale.
Reading time: ~28 minutes
Introduction: The Production Gap
You’ve implemented LinUCB or Thompson Sampling. It works great in simulation. Now what?
The gap between research and production is enormous:
- Offline evaluation: How do you validate performance before going live?
- Architecture: What components do you need? How do they interact?
- Logging: What data must you capture? How to handle delayed rewards?
- Monitoring: What metrics indicate problems? When to trigger alerts?
- Safety: How to prevent disasters? Circuit breakers? Fallbacks?
- Deployment: How to roll out gradually? Validate at each stage?
This post bridges that gap. By the end, you’ll have:
- Complete offline evaluation pipeline (IPS, Doubly Robust)
- Production architecture blueprint (8 components)
- Monitoring dashboard specification
- Pre-deployment checklist (56 criteria across 7 phases)
Let’s deploy safely.
Offline Evaluation: Validate Before You Deploy
Critical problem: You can’t A/B test your bandit against production until it’s already in production. But deploying an untested bandit risks disasters.
Solution: Offline evaluation—estimate bandit performance using historical logged data.
The Counterfactual Problem
# Historical data from production logging policy π₀
logged_data = [
(context₁, action₁, reward₁), # π₀ chose action₁
(context₂, action₂, reward₂), # π₀ chose action₂
...
]
# Question: How would our new policy π₁ perform?
# Problem: We only observed rewards for actions π₀ chose,
# not for actions π₁ would have chosen
Counterfactual inference: Estimating what would have happened under a different policy using observed data from another policy.
Three Offline Evaluation Methods
| Method | Bias | Variance | When to Use |
|---|---|---|---|
| Replay | High (if policies differ) | Low | Policies are very similar |
| IPS (Inverse Propensity Score) | Unbiased | High | Have propensity scores, small policy divergence |
| Doubly Robust | Unbiased | Lower | Best of both worlds, recommended |
Method 1: Replay Evaluation (Biased but Simple)
Idea: Replay logged data, only count rounds where new policy would have made same decision as logging policy.
Implementation
import numpy as np
from typing import List, Tuple, Dict
def replay_evaluation(logged_data: List[Tuple], new_policy) -> float:
"""
Replay evaluation: only use data where policies agree.
Biased if new policy differs significantly from logging policy.
Args:
logged_data: List of (context, action_logged, reward) tuples
new_policy: Policy to evaluate (must have select_action method)
Returns:
estimated_value: Estimated average reward
"""
matching_rewards = []
for context, action_logged, reward in logged_data:
# What would new policy choose?
action_new = new_policy.select_action(context)
# Only count if policies agree
if action_new == action_logged:
matching_rewards.append(reward)
if len(matching_rewards) == 0:
return np.nan # No matching data
return np.mean(matching_rewards)
# Example usage
if __name__ == "__main__":
from contextual_bandits import LinUCB
# Load historical data
# logged_data = load_from_database()
# Simulated data
logged_data = [
(np.random.randn(10), np.random.randint(3), np.random.random())
for _ in range(1000)
]
# New policy to evaluate
new_policy = LinUCB(n_actions=3, n_features=10, alpha=1.0)
# Estimate performance
estimated_reward = replay_evaluation(logged_data, new_policy)
print(f"Estimated average reward: {estimated_reward:.3f}")
# Coverage: what fraction of data was usable?
coverage = sum(
1 for ctx, a_log, _ in logged_data
if new_policy.select_action(ctx) == a_log
) / len(logged_data)
print(f"Policy coverage: {coverage:.1%}")
When to Use Replay
✅ Use when:
- New policy is similar to logging policy (high coverage >50%)
- Need simple, interpretable evaluation
- Quick validation during development
❌ Limitations:
- Biased: Systematically underestimates performance if new policy is better
- Low coverage: Wastes most data if policies differ
- Can’t evaluate exploration: Only uses data where policies agree
Method 2: Inverse Propensity Score (IPS)
Idea: Reweight observations by inverse probability that logging policy would choose that action.
Mathematical Foundation
Logging policy π₀ chooses actions with probabilities p₀(a|x).
We want to estimate value of new policy π₁:
IPS estimator:
where:
- π₁(aᵢ|xᵢ) = probability new policy chooses action aᵢ given context xᵢ
- π₀(aᵢ|xᵢ) = probability logging policy chose action aᵢ (propensity score)
- rᵢ = observed reward
Intuition: If logging policy rarely chose action A (small p₀), but new policy chooses it often (large π₁), upweight those observations.
Implementation
def inverse_propensity_score(
logged_data: List[Tuple],
new_policy,
propensity_scores: List[float],
clip: float = 0.01
) -> Tuple[float, float]:
"""
Inverse Propensity Score (IPS) evaluation.
Unbiased estimator that reweights observations by propensity scores.
Args:
logged_data: List of (context, action_logged, reward) tuples
new_policy: Policy to evaluate
propensity_scores: P(action_logged | context) from logging policy
clip: Minimum propensity score (prevent extreme weights)
Returns:
estimated_value: Estimated average reward
effective_n: Effective sample size (variance indicator)
"""
weights = []
weighted_rewards = []
for (context, action_logged, reward), prop_score in zip(logged_data, propensity_scores):
# Clip propensity score to prevent extreme weights
prop_score = max(prop_score, clip)
# Would new policy choose this action?
action_new = new_policy.select_action(context)
# Importance weight: π₁(a|x) / π₀(a|x)
if action_new == action_logged:
weight = 1.0 / prop_score # π₁(a|x) = 1 (deterministic)
else:
weight = 0.0 # π₁(a|x) = 0
weights.append(weight)
weighted_rewards.append(weight * reward)
# IPS estimate
estimated_value = np.sum(weighted_rewards) / len(logged_data)
# Effective sample size (measures variance)
# ESS = (Σw)² / Σw²
sum_weights = np.sum(weights)
sum_weights_sq = np.sum([w**2 for w in weights])
effective_n = sum_weights**2 / sum_weights_sq if sum_weights_sq > 0 else 0
return estimated_value, effective_n
def ips_with_confidence_interval(
logged_data: List[Tuple],
new_policy,
propensity_scores: List[float],
alpha: float = 0.05
) -> Dict[str, float]:
"""
IPS with confidence interval using bootstrap.
Args:
logged_data: Historical data
new_policy: Policy to evaluate
propensity_scores: Propensity scores
alpha: Confidence level (0.05 = 95% CI)
Returns:
dict with 'estimate', 'ci_lower', 'ci_upper', 'effective_n'
"""
n_bootstrap = 1000
estimates = []
n = len(logged_data)
for _ in range(n_bootstrap):
# Bootstrap resample
indices = np.random.choice(n, size=n, replace=True)
sample_data = [logged_data[i] for i in indices]
sample_props = [propensity_scores[i] for i in indices]
# IPS on this sample
estimate, _ = inverse_propensity_score(sample_data, new_policy, sample_props)
estimates.append(estimate)
# Point estimate on full data
point_estimate, effective_n = inverse_propensity_score(
logged_data, new_policy, propensity_scores
)
# Confidence interval from bootstrap distribution
ci_lower = np.percentile(estimates, 100 * alpha / 2)
ci_upper = np.percentile(estimates, 100 * (1 - alpha / 2))
return {
'estimate': point_estimate,
'ci_lower': ci_lower,
'ci_upper': ci_upper,
'effective_n': effective_n,
'std': np.std(estimates)
}
# Example usage
if __name__ == "__main__":
# Simulate logged data with known propensities
n = 5000
n_actions = 5
n_features = 10
logged_data = []
propensity_scores = []
for _ in range(n):
context = np.random.randn(n_features)
# Logging policy: ε-greedy with ε=0.2
if np.random.random() < 0.2:
action = np.random.randint(n_actions) # Random
prop_score = 0.2 / n_actions # Uniform exploration
else:
action = 0 # Always choose action 0 when exploiting
prop_score = 0.8
# Simulate reward
true_best = np.argmax([np.sum(context[:2]), np.sum(context[2:4]),
np.sum(context[4:6]), np.sum(context[6:8]),
np.sum(context[8:])])
reward = 1.0 if action == true_best else 0.3
reward += np.random.normal(0, 0.1)
logged_data.append((context, action, reward))
propensity_scores.append(prop_score)
# Evaluate new policy
new_policy = LinUCB(n_actions=n_actions, n_features=n_features, alpha=1.0)
# Train on logged data (for fair comparison)
for context, action, reward in logged_data[:3000]:
new_policy.update(action, context, reward)
# Evaluate
result = ips_with_confidence_interval(
logged_data[3000:], new_policy, propensity_scores[3000:]
)
print("IPS Evaluation Results:")
print(f" Estimated reward: {result['estimate']:.3f}")
print(f" 95% CI: [{result['ci_lower']:.3f}, {result['ci_upper']:.3f}]")
print(f" Effective sample size: {result['effective_n']:.0f} / {len(logged_data) - 3000}")
print(f" Standard error: {result['std']:.3f}")
IPS Challenges
⚠️ High variance: If π₀(a|x) is small and π₁(a|x) is large, weights explode.
Example: Logging policy chose action A with 1% probability. New policy always chooses A. Weight = 1/0.01 = 100×.
Solutions:
- Clipping: Cap propensity scores at minimum (e.g., 0.01)
- Normalization: Self-normalized IPS (divide by sum of weights)
- Doubly Robust: Combine with model-based predictions
Method 3: Doubly Robust Estimation (Recommended)
Idea: Combine IPS with a reward model. Get benefits of both, robust to misspecification of either.
Mathematical Foundation
Doubly Robust estimator:
where is a learned reward model.
Components:
- Direct method: — model-based prediction
- IPS correction: — corrects model errors using observed rewards
Why “doubly robust”:
- If reward model is perfect: IPS correction = 0, uses model
- If reward model is terrible but propensities correct: IPS correction fixes it
- Unbiased if either model or propensities are correct (not necessarily both)
Implementation
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
import numpy as np
class DoublyRobustEvaluator:
"""
Doubly Robust offline evaluation.
Combines reward model predictions with IPS corrections.
More robust and lower variance than pure IPS.
"""
def __init__(self, n_actions: int, n_features: int):
"""
Args:
n_actions: Number of actions
n_features: Context dimensionality
"""
self.n_actions = n_actions
self.n_features = n_features
# Reward models for each action
self.reward_models = [
RandomForestRegressor(n_estimators=100, max_depth=10)
for _ in range(n_actions)
]
self.scaler = StandardScaler()
self.is_trained = False
def train_reward_models(self, logged_data: List[Tuple]):
"""
Train reward models on logged data.
Args:
logged_data: List of (context, action, reward) tuples
"""
# Organize data by action
action_data = {a: {'X': [], 'y': []} for a in range(self.n_actions)}
for context, action, reward in logged_data:
action_data[action]['X'].append(context)
action_data[action]['y'].append(reward)
# Fit scaler on all contexts
all_contexts = [ctx for ctx, _, _ in logged_data]
self.scaler.fit(all_contexts)
# Train model for each action
for a in range(self.n_actions):
if len(action_data[a]['X']) > 10: # Need minimum data
X = self.scaler.transform(action_data[a]['X'])
y = action_data[a]['y']
self.reward_models[a].fit(X, y)
self.is_trained = True
def predict_reward(self, context: np.ndarray, action: int) -> float:
"""
Predict reward for context-action pair.
Args:
context: Context features
action: Action index
Returns:
predicted_reward: Model's prediction
"""
if not self.is_trained:
return 0.0 # No model yet
context_scaled = self.scaler.transform([context])
return self.reward_models[action].predict(context_scaled)[0]
def evaluate(
self,
logged_data: List[Tuple],
new_policy,
propensity_scores: List[float],
clip: float = 0.01
) -> Dict[str, float]:
"""
Doubly Robust evaluation.
Args:
logged_data: Historical data
new_policy: Policy to evaluate
propensity_scores: Logging policy probabilities
clip: Minimum propensity score
Returns:
dict with estimates and diagnostics
"""
if not self.is_trained:
raise ValueError("Must train reward models first")
n = len(logged_data)
direct_estimates = []
ips_corrections = []
dr_estimates = []
for (context, action_logged, reward), prop_score in zip(logged_data, propensity_scores):
# Clip propensity
prop_score = max(prop_score, clip)
# New policy's action
action_new = new_policy.select_action(context)
# Direct method: predict reward for new policy's action
r_hat_new = self.predict_reward(context, action_new)
direct_estimates.append(r_hat_new)
# IPS correction term
if action_new == action_logged:
# Model prediction for logged action
r_hat_logged = self.predict_reward(context, action_logged)
# Correction: (r - r_hat) / p
correction = (reward - r_hat_logged) / prop_score
ips_corrections.append(correction)
else:
ips_corrections.append(0.0)
# Doubly Robust: direct + correction
dr_estimates.append(r_hat_new + ips_corrections[-1])
return {
'doubly_robust': np.mean(dr_estimates),
'direct_method': np.mean(direct_estimates),
'ips_correction': np.mean(ips_corrections),
'std': np.std(dr_estimates),
'stderr': np.std(dr_estimates) / np.sqrt(n)
}
def evaluate_with_ci(
self,
logged_data: List[Tuple],
new_policy,
propensity_scores: List[float],
alpha: float = 0.05,
n_bootstrap: int = 1000
) -> Dict[str, float]:
"""
Doubly Robust evaluation with bootstrap confidence intervals.
Args:
logged_data: Historical data
new_policy: Policy to evaluate
propensity_scores: Logging probabilities
alpha: Confidence level
n_bootstrap: Number of bootstrap samples
Returns:
dict with point estimate and confidence interval
"""
n = len(logged_data)
estimates = []
for _ in range(n_bootstrap):
# Bootstrap resample
indices = np.random.choice(n, size=n, replace=True)
sample_data = [logged_data[i] for i in indices]
sample_props = [propensity_scores[i] for i in indices]
# Evaluate on sample
result = self.evaluate(sample_data, new_policy, sample_props)
estimates.append(result['doubly_robust'])
# Point estimate on full data
point_result = self.evaluate(logged_data, new_policy, propensity_scores)
# Confidence interval
ci_lower = np.percentile(estimates, 100 * alpha / 2)
ci_upper = np.percentile(estimates, 100 * (1 - alpha / 2))
return {
**point_result,
'ci_lower': ci_lower,
'ci_upper': ci_upper
}
# Example usage
if __name__ == "__main__":
# Generate logged data
n_train = 10000
n_test = 2000
n_actions = 5
n_features = 10
def generate_data(n):
data = []
props = []
for _ in range(n):
context = np.random.randn(n_features)
# True best action (unknown to evaluator)
true_rewards = [
np.sum(context[:2]) + np.random.normal(0, 0.1),
np.sum(context[2:4]) + np.random.normal(0, 0.1),
np.sum(context[4:6]) + np.random.normal(0, 0.1),
np.sum(context[6:8]) + np.random.normal(0, 0.1),
np.sum(context[8:]) + np.random.normal(0, 0.1)
]
# Logging policy: ε-greedy (ε=0.3)
if np.random.random() < 0.3:
action = np.random.randint(n_actions)
prop = 0.3 / n_actions
else:
action = 0 # Always exploit action 0
prop = 0.7
reward = true_rewards[action]
data.append((context, action, reward))
props.append(prop)
return data, props
train_data, train_props = generate_data(n_train)
test_data, test_props = generate_data(n_test)
# Train reward models
print("Training reward models...")
evaluator = DoublyRobustEvaluator(n_actions, n_features)
evaluator.train_reward_models(train_data)
# Create new policy
new_policy = LinUCB(n_actions=n_actions, n_features=n_features, alpha=1.0)
# Train new policy on first half of train data
for context, action, reward in train_data[:5000]:
new_policy.update(action, context, reward)
# Evaluate
print("\nEvaluating new policy...")
result = evaluator.evaluate_with_ci(test_data, new_policy, test_props)
print(f"\nDoubly Robust Evaluation:")
print(f" Estimate: {result['doubly_robust']:.3f}")
print(f" 95% CI: [{result['ci_lower']:.3f}, {result['ci_upper']:.3f}]")
print(f" Direct method: {result['direct_method']:.3f}")
print(f" IPS correction: {result['ips_correction']:.3f}")
print(f" Std error: {result['stderr']:.4f}")
When to Use Each Method
| Method | Bias | Variance | Best For |
|---|---|---|---|
| Replay | High | Low | Quick validation, similar policies |
| IPS | None | High | Have good propensities, policies not too different |
| Doubly Robust | None* | Medium | Production recommendation |
*Unbiased if either model or propensities are correct
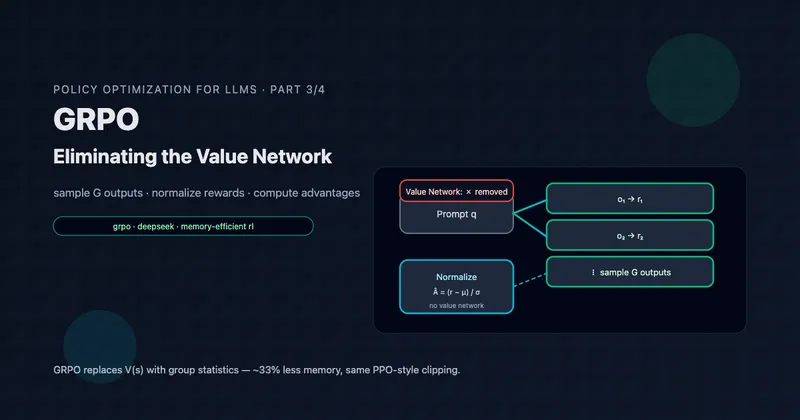
Production Architecture: 8 Core Components
Here’s the complete system architecture for production contextual bandits:
Component Details
1. API Service (Context Builder)
Purpose: Build context features from request, filter available actions
class ContextBuilder:
"""
Builds context vector from raw request data.
Extracts user features, item features, situational features.
Handles missing values, normalization, feature engineering.
"""
def __init__(self, feature_config: Dict):
self.feature_config = feature_config
self.scaler = StandardScaler()
def build_context(self, request: Dict) -> np.ndarray:
"""
Build context vector from request.
Args:
request: Raw request data (user_id, session_data, etc.)
Returns:
context: Feature vector for bandit
"""
features = []
# User features
user_id = request.get('user_id')
user_features = self._get_user_features(user_id)
features.extend(user_features)
# Situational features
time_features = self._get_time_features(request.get('timestamp'))
features.extend(time_features)
# Device features
device_features = self._get_device_features(request.get('device'))
features.extend(device_features)
# Convert to array and normalize
context = np.array(features)
return self.scaler.transform([context])[0]
def filter_actions(self, request: Dict, all_actions: List) -> List:
"""
Filter actions based on business constraints.
Args:
request: User request
all_actions: All possible actions
Returns:
eligible_actions: Actions that can be shown to this user
"""
eligible = []
for action in all_actions:
# Business rules
if self._is_eligible(action, request):
eligible.append(action)
return eligible
def _is_eligible(self, action, request) -> bool:
"""Check if action satisfies constraints."""
# Example constraints:
# - User hasn't seen this in last 24h
# - Action is available in user's region
# - User meets age/subscription requirements
return True # Implement actual logic
2. Policy Service
Purpose: Execute bandit algorithm, return action with propensity
class PolicyService:
"""
Serves bandit policy decisions.
Loads model from cache, computes action, logs propensity.
"""
def __init__(self, model_cache, policy_type='linucb'):
self.cache = model_cache
self.policy_type = policy_type
self.policy = None
def load_policy(self, version: str = 'latest'):
"""Load policy from cache or storage."""
self.policy = self.cache.get(f'policy:{version}')
if self.policy is None:
raise ValueError(f"Policy version {version} not found")
def select_action(
self,
context: np.ndarray,
eligible_actions: List[int]
) -> Dict:
"""
Select action using policy.
Args:
context: Feature vector
eligible_actions: Available actions
Returns:
dict with 'action', 'propensity', 'scores', 'version'
"""
# Get scores for all eligible actions
scores = {}
for action in eligible_actions:
if self.policy_type == 'linucb':
scores[action] = self._compute_ucb(context, action)
elif self.policy_type == 'thompson':
scores[action] = self._sample_thompson(context, action)
# Choose action
chosen_action = max(scores.keys(), key=lambda a: scores[a])
# Compute propensity (for offline eval)
# For deterministic policies: propensity = 1.0 for chosen, 0 for others
# For stochastic: use softmax or actual sampling probability
propensity = 1.0 # Deterministic
return {
'action': chosen_action,
'propensity': propensity,
'scores': scores,
'version': self.policy.version,
'timestamp': time.time()
}
def _compute_ucb(self, context, action):
"""Compute UCB score for action."""
# Implementation depends on LinUCB details
return self.policy.get_ucb(context, action)
def _sample_thompson(self, context, action):
"""Sample from posterior for action."""
return self.policy.sample_reward(context, action)
3. Event Logger
Purpose: Log all decisions with full context for offline evaluation
Critical data to log:
{
# Decision event
"event_id": "uuid",
"timestamp": "2025-11-15T10:30:45Z",
"user_id": "user_12345",
# Context (features)
"context": [0.5, -1.2, 0.3, ...], # Full feature vector
"context_metadata": {
"user_tenure_days": 45,
"device": "mobile",
"time_of_day": "morning"
},
# Decision
"action_chosen": 42,
"eligible_actions": [42, 17, 91, ...],
"propensity": 1.0, # P(action_chosen | context)
# Model
"policy_version": "v1.2.3",
"algorithm": "linucb",
"exploration_param": {"alpha": 1.0},
# Scores (for debugging)
"action_scores": {42: 0.85, 17: 0.72, 91: 0.68},
# Reward (initially null, filled later)
"reward": null,
"reward_timestamp": null
}
Implementation:
class EventLogger:
"""
Logs bandit decisions to Kafka/Kinesis for downstream processing.
"""
def __init__(self, kafka_producer):
self.producer = kafka_producer
self.topic = 'bandit-decisions'
def log_decision(
self,
event_id: str,
context: np.ndarray,
action: int,
propensity: float,
metadata: Dict
):
"""
Log a bandit decision event.
Args:
event_id: Unique identifier for this decision
context: Feature vector
action: Chosen action
propensity: P(action | context)
metadata: Additional context (user_id, version, etc.)
"""
event = {
'event_id': event_id,
'timestamp': time.time(),
'context': context.tolist(),
'action': action,
'propensity': propensity,
**metadata
}
# Send to Kafka
self.producer.send(self.topic, value=event)
# Also log to structured storage (S3, BigQuery)
self._archive_to_storage(event)
4. Reward Collector
Purpose: Match rewards to decisions, handle delayed rewards
class RewardCollector:
"""
Collects rewards and matches them to logged decisions.
Handles delayed rewards (e.g., purchases hours after click).
"""
def __init__(self, event_store):
self.event_store = event_store
def record_reward(
self,
event_id: str,
reward: float,
reward_timestamp: float
):
"""
Record reward for a decision event.
Args:
event_id: ID of the decision event
reward: Observed reward value
reward_timestamp: When reward occurred
"""
# Update event with reward
self.event_store.update(
event_id,
{
'reward': reward,
'reward_timestamp': reward_timestamp,
'reward_delay': reward_timestamp - event['timestamp']
}
)
def match_rewards_batch(self, reward_events: List[Dict]):
"""
Batch process reward events and match to decisions.
For example: purchases (rewards) matched to product clicks (decisions)
based on user_id and time window.
"""
for reward_event in reward_events:
# Find corresponding decision event
decision_events = self.event_store.find(
user_id=reward_event['user_id'],
timestamp_after=reward_event['timestamp'] - 3600, # 1 hour window
timestamp_before=reward_event['timestamp']
)
# Attribute reward to most recent eligible decision
if decision_events:
latest_decision = decision_events[-1]
self.record_reward(
latest_decision['event_id'],
reward_event['reward'],
reward_event['timestamp']
)
5. Offline Evaluator
Purpose: Continuously evaluate policy performance on historical data
class OfflineEvaluator:
"""
Continuously evaluates policy candidates using logged data.
Runs IPS, Doubly Robust, and other offline metrics.
"""
def __init__(self):
self.evaluators = {
'ips': IPSEvaluator(),
'doubly_robust': DoublyRobustEvaluator(),
'replay': ReplayEvaluator()
}
def evaluate_policy(
self,
policy_candidate,
evaluation_data: List[Tuple],
propensity_scores: List[float]
) -> Dict:
"""
Evaluate policy candidate on historical data.
Returns:
dict with estimates from multiple methods
"""
results = {}
for name, evaluator in self.evaluators.items():
estimate = evaluator.evaluate(
evaluation_data,
policy_candidate,
propensity_scores
)
results[name] = estimate
return results
def compare_policies(
self,
policies: Dict[str, Policy],
evaluation_data: List[Tuple],
propensity_scores: List[float]
) -> pd.DataFrame:
"""
Compare multiple policy candidates.
Returns:
DataFrame with comparison results
"""
comparison = []
for name, policy in policies.items():
results = self.evaluate_policy(
policy, evaluation_data, propensity_scores
)
comparison.append({'policy': name, **results})
return pd.DataFrame(comparison)
6. Policy Trainer
Purpose: Train new policy versions on logged data
class PolicyTrainer:
"""
Trains bandit policies on logged reward data.
Handles batch training, model versioning, validation.
"""
def __init__(self, algorithm_type='linucb'):
self.algorithm_type = algorithm_type
def train(
self,
training_data: List[Tuple],
validation_data: List[Tuple],
hyperparams: Dict
) -> Policy:
"""
Train policy on logged data.
Args:
training_data: (context, action, reward) tuples
validation_data: Held-out data for validation
hyperparams: Algorithm hyperparameters
Returns:
trained_policy: Trained policy ready for deployment
"""
# Initialize policy
if self.algorithm_type == 'linucb':
policy = LinUCB(**hyperparams)
elif self.algorithm_type == 'thompson':
policy = LinearThompsonSampling(**hyperparams)
# Train on batch data
for context, action, reward in training_data:
policy.update(action, context, reward)
# Validate
val_performance = self._validate(policy, validation_data)
# Version and save
policy.version = self._generate_version()
policy.validation_metrics = val_performance
return policy
def _validate(self, policy, validation_data):
"""Compute validation metrics."""
# Replay evaluation on validation set
total_reward = 0
matches = 0
for context, action_logged, reward in validation_data:
action_pred = policy.select_action(context)
if action_pred == action_logged:
total_reward += reward
matches += 1
return {
'avg_reward': total_reward / matches if matches > 0 else 0,
'coverage': matches / len(validation_data)
}
7. Monitor Service
Purpose: Track KPIs, detect anomalies, trigger alerts
Key metrics to monitor:
class BanditMonitor:
"""
Monitors bandit system health and performance.
Tracks KPIs, detects anomalies, sends alerts.
"""
def __init__(self):
self.metrics = {
# Performance metrics
'average_reward': RollingAverage(window=1000),
'action_distribution': Counter(),
'regret_estimate': RollingAverage(window=1000),
# System metrics
'latency_p50': Percentile(50),
'latency_p99': Percentile(99),
'error_rate': RollingAverage(window=1000),
# Exploration metrics
'exploration_rate': RollingAverage(window=1000),
'novel_contexts': Counter()
}
def log_decision(self, decision_event: Dict):
"""Log metrics from a decision event."""
# Update performance metrics
if 'reward' in decision_event and decision_event['reward'] is not None:
self.metrics['average_reward'].update(decision_event['reward'])
# Track action distribution
self.metrics['action_distribution'][decision_event['action']] += 1
# Track latency
if 'latency_ms' in decision_event:
self.metrics['latency_p99'].update(decision_event['latency_ms'])
def check_alerts(self) -> List[Alert]:
"""Check for alert conditions."""
alerts = []
# Alert: Reward drop
if self.metrics['average_reward'].value < 0.5 * self.baseline_reward:
alerts.append(Alert(
severity='high',
message='Average reward dropped >50% below baseline',
metric='average_reward',
value=self.metrics['average_reward'].value
))
# Alert: Action imbalance
action_dist = self.metrics['action_distribution']
if max(action_dist.values()) > 0.9 * sum(action_dist.values()):
alerts.append(Alert(
severity='medium',
message='Single action getting >90% of traffic',
metric='action_distribution'
))
# Alert: High latency
if self.metrics['latency_p99'].value > 200: # ms
alerts.append(Alert(
severity='medium',
message='P99 latency >200ms',
metric='latency_p99',
value=self.metrics['latency_p99'].value
))
return alerts
Dashboard KPIs:
| Category | Metric | Alert Threshold |
|---|---|---|
| Performance | Average reward | <80% of baseline |
| Estimated regret | Growing linearly | |
| Policy value (offline) | Decreasing | |
| Exploration | Action entropy | <0.5 (too concentrated) |
| Exploration rate | <5% (under-exploring) | |
| System | P99 latency | >200ms |
| Error rate | >1% | |
| Cache hit rate | <95% |
8. Safety Layer
Purpose: Prevent disasters, provide fallbacks
class SafetyLayer:
"""
Safety mechanisms for production bandit systems.
Implements circuit breakers, rate limits, fallback policies.
"""
def __init__(self, fallback_policy):
self.fallback_policy = fallback_policy
self.circuit_breaker = CircuitBreaker(
failure_threshold=10,
timeout=60 # seconds
)
self.rate_limiter = RateLimiter(max_requests_per_second=1000)
def safe_select_action(
self,
policy,
context: np.ndarray,
eligible_actions: List[int]
) -> Dict:
"""
Select action with safety checks.
Falls back to safe policy if main policy fails.
"""
try:
# Check rate limit
if not self.rate_limiter.allow_request():
raise RateLimitExceeded("Too many requests")
# Check circuit breaker
if self.circuit_breaker.is_open():
raise CircuitBreakerOpen("Policy service unavailable")
# Try main policy
result = policy.select_action(context, eligible_actions)
# Sanity checks
self._validate_result(result, eligible_actions)
self.circuit_breaker.record_success()
return result
except Exception as e:
# Record failure
self.circuit_breaker.record_failure()
# Log error
logger.error(f"Policy selection failed: {e}")
# Fallback to safe policy
return self.fallback_policy.select_action(context, eligible_actions)
def _validate_result(self, result: Dict, eligible_actions: List[int]):
"""Sanity check policy output."""
# Check action is eligible
if result['action'] not in eligible_actions:
raise ValueError(f"Invalid action {result['action']}")
# Check scores are reasonable
if any(score > 100 or score < -100 for score in result['scores'].values()):
raise ValueError("Unreasonable action scores")
# Check propensity
if not (0 <= result['propensity'] <= 1):
raise ValueError(f"Invalid propensity {result['propensity']}")
Monitoring Dashboard Specification
Overview Dashboard
┌─────────────────────────────────────────────────────────────────┐
│ Contextual Bandit System - Production Dashboard │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 📊 PERFORMANCE METRICS │
│ ┌─────────────────┬─────────────────┬─────────────────┐ │
│ │ Avg Reward │ Estimated Regret│ Policy Value │ │
│ │ 0.732 ▲ +2.1% │ 142.3 ▼ -5.2% │ 0.745 ▲ +1.8% │ │
│ │ (vs baseline) │ (cumulative) │ (offline eval) │ │
│ └─────────────────┴─────────────────┴─────────────────┘ │
│ │
│ 🎯 EXPLORATION METRICS │
│ ┌─────────────────┬─────────────────┬─────────────────┐ │
│ │ Action Entropy │ Exploration % │ Novel Contexts │ │
│ │ 1.83 / 2.32 │ 12.4% │ 347 / hour │ │
│ │ (healthy) │ (good) │ (normal) │ │
│ └─────────────────┴─────────────────┴─────────────────┘ │
│ │
│ ⚙️ SYSTEM HEALTH │
│ ┌─────────────────┬─────────────────┬─────────────────┐ │
│ │ P99 Latency │ Error Rate │ Cache Hit Rate │ │
│ │ 87ms ✓ │ 0.12% ✓ │ 98.3% ✓ │ │
│ │ (<200ms) │ (<1%) │ (>95%) │ │
│ └─────────────────┴─────────────────┴─────────────────┘ │
│ │
│ 📈 REWARD OVER TIME (Last 24h) │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 0.8┤ ╭──╮ │ │
│ │ 0.7┤ ╭─╮ ╭────╯ ╰─╮ │ │
│ │ 0.6┤ ╭───────╯ ╰──────────────╯ ╰─╮ │ │
│ │ 0.5┤ ╭─────╯ ╰──── │ │
│ │ └──────────────────────────────────────────────────── │ │
│ │ 00:00 06:00 12:00 18:00 24:00 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ 🎬 ACTION DISTRIBUTION (Last 1000 decisions) │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Action 1: ████████████████████░░░░░░░░░░ 45.2% │ │
│ │ Action 2: ████████████░░░░░░░░░░░░░░░░░░ 28.7% │ │
│ │ Action 3: ██████░░░░░░░░░░░░░░░░░░░░░░░░ 15.3% │ │
│ │ Action 4: ████░░░░░░░░░░░░░░░░░░░░░░░░░░ 8.1% │ │
│ │ Action 5: ██░░░░░░░░░░░░░░░░░░░░░░░░░░░░ 2.7% │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ⚠️ ACTIVE ALERTS: 0 │
│ │
└─────────────────────────────────────────────────────────────────┘
Alert Configuration
alerts:
- name: reward_drop
condition: avg_reward < 0.8 * baseline_reward
severity: high
notification: pagerduty
- name: action_concentration
condition: max(action_dist) / sum(action_dist) > 0.9
severity: medium
notification: slack
- name: exploration_too_low
condition: exploration_rate < 0.05
severity: medium
notification: slack
- name: high_latency
condition: p99_latency > 200
severity: medium
notification: slack
- name: high_error_rate
condition: error_rate > 0.01
severity: high
notification: pagerduty
Deployment Workflow: Research to Production
Phase 1: Research & Development (Week 1-2)
Objectives:
- Choose algorithm (LinUCB, Thompson Sampling, etc.)
- Implement and test locally
- Validate on simulated data
Checklist:
- Algorithm implemented with tests
- Regret curves show sublinear growth
- Hyperparameters tuned
- Code reviewed
Phase 2: Offline Evaluation (Week 3-4)
Objectives:
- Validate on historical production data
- Compare to baseline policy
- Estimate expected lift
Checklist:
- Historical data prepared (context, actions, rewards, propensities)
- Offline evaluation implemented (IPS, Doubly Robust)
- New policy shows improvement over baseline
- Confidence intervals computed
- Results reviewed by stakeholders
Example results to present:
Offline Evaluation Results:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Baseline Policy (Production):
Average reward: 0.650
New Policy (LinUCB):
Doubly Robust estimate: 0.732 ± 0.018
95% CI: [0.714, 0.750]
Estimated lift: +12.6%
Statistical significance: p < 0.001
Recommendation: Proceed to staging deployment
Phase 3: Staging Deployment (Week 5)
Objectives:
- Deploy to staging environment
- Validate end-to-end system
- Test logging, monitoring, safety mechanisms
Checklist:
- Policy service deployed to staging
- Logging pipeline configured
- Monitoring dashboard created
- Safety mechanisms tested (circuit breaker, fallback)
- Load testing passed (latency <100ms at 1000 RPS)
- Error handling tested
- Staging traffic validated (1 week of data)
Phase 4: Shadow Mode (Week 6-7)
Objectives:
- Run new policy in parallel with production
- Log what decisions new policy would make
- No user impact (don’t show new policy’s actions)
Checklist:
- Shadow logging enabled
- Compare decisions: new policy vs production
- Analyze disagreement (where do policies differ?)
- Offline eval on shadow data confirms expected performance
- No bugs or anomalies detected
Phase 5: Canary Deployment (Week 8-9)
Objectives:
- Route 5% of traffic to new policy
- Monitor closely for issues
- Gradually increase if successful
Canary schedule:
- Week 8: 5% traffic
- Week 9: 10% → 20% → 50%
Checklist:
- 5% traffic routed to new policy
- Monitoring dashboard shows healthy metrics
- No increase in errors or latency
- Reward metrics stable or improving
- Stakeholder approval to increase traffic
- Gradual increase to 50%
Phase 6: Full Rollout (Week 10)
Objectives:
- Route 100% of traffic
- Monitor for 1 week
- Declare production-ready
Checklist:
- 100% traffic on new policy
- All metrics stable
- Offline evaluation confirms expected lift
- Documentation updated
- Runbook created for on-call
- Rollback plan documented
Phase 7: Continuous Improvement (Ongoing)
Objectives:
- Retrain periodically
- Monitor for distribution drift
- Iterate on features and hyperparameters
Ongoing tasks:
- Weekly offline evaluation
- Monthly policy retraining
- Quarterly hyperparameter tuning
- Feature engineering experiments
Pre-Deployment Checklist
Comprehensive 56-Point Checklist
Algorithm & Model (8 items)
- Algorithm selected with justification
- Hyperparameters tuned on offline data
- Regret bounds validated (sublinear growth)
- Code reviewed by at least 2 engineers
- Unit tests pass (>90% coverage)
- Integration tests pass
- Model serialization/deserialization tested
- Model versioning implemented
Offline Evaluation (8 items)
- Historical data collected (min 10k decisions)
- Propensity scores logged or estimated
- IPS evaluation implemented
- Doubly Robust evaluation implemented
- Confidence intervals computed
- Statistical significance test passed (p < 0.05)
- Comparison to baseline documented
- Results presented to stakeholders
Logging Infrastructure (8 items)
- Event logger implemented (Kafka/Kinesis)
- All required fields logged (context, action, propensity)
- Reward collector implemented
- Delayed reward handling tested
- Log archival to S3/BigQuery configured
- Log retention policy defined
- PII/sensitive data handling reviewed
- Logging performance tested (no bottlenecks)
Serving Infrastructure (8 items)
- Policy service deployed
- Context builder tested
- Action filtering logic validated
- Cache layer configured (Redis)
- Load balancing configured
- Latency SLA met (P99 <200ms)
- Error handling robust
- Circuit breaker implemented
Monitoring & Alerting (8 items)
- Dashboard created (Grafana/DataDog)
- Key metrics tracked (reward, latency, errors)
- Alert rules configured
- Alert routing to PagerDuty/Slack
- On-call runbook created
- Log aggregation (ELK/Splunk)
- Anomaly detection configured
- Weekly review process defined
Safety & Reliability (8 items)
- Fallback policy implemented
- Circuit breaker tested
- Rate limiting configured
- Graceful degradation tested
- Rollback plan documented
- Disaster recovery plan
- Security review passed
- Compliance review passed (GDPR, etc.)
Deployment Process (8 items)
- Staging environment validated
- Shadow mode run (1+ week)
- Canary deployment plan defined
- Gradual rollout schedule
- A/B test designed (if needed)
- Rollback criteria defined
- Stakeholder sign-off obtained
- Go-live date scheduled
Common Pitfalls & Solutions
Pitfall 1: Insufficient Logging
Problem: Missing propensity scores or context features makes offline evaluation impossible.
Solution:
- Log EVERYTHING: full context vector, all eligible actions, propensity for chosen action
- Include metadata: model version, hyperparameters, timestamp
- Test logging before deployment
Pitfall 2: Ignoring Delayed Rewards
Problem: Purchase happens hours after click. Naive logging misses the connection.
Solution:
- Implement reward collector with attribution window (e.g., 24 hours)
- Log decision_id with user_id to enable matching
- Use last-click or probabilistic attribution
Pitfall 3: Not Monitoring Exploration
Problem: Policy converges to always choosing one action (stopped exploring).
Solution:
- Track action entropy: H = -Σ p(a) log p(a)
- Alert if entropy drops below threshold
- Ensure exploration parameter (ε, α) is properly tuned
Pitfall 4: Deploying Without Offline Validation
Problem: “It worked in simulation!” (then fails in production)
Solution:
- ALWAYS run offline evaluation on real historical data
- Require statistical significance (p < 0.05, CI doesn’t include baseline)
- Get stakeholder approval before deploying
Pitfall 5: Inadequate Safety Mechanisms
Problem: Policy fails, routes 100% of traffic to broken action.
Solution:
- Implement circuit breaker (fallback after N failures)
- Rate limits prevent runaway behavior
- Gradual rollout (canary deployment)
Pitfall 6: Forgetting About Distribution Drift
Problem: Policy trained on November data, deployed in December (holiday shopping behavior differs).
Solution:
- Monitor for distribution drift (compare current vs training contexts)
- Retrain periodically (weekly or monthly)
- Use constant small exploration (ε = 0.05) to adapt
Pitfall 7: Over-Optimizing Exploration
Problem: Spending weeks tuning α from 1.0 to 0.95 for 0.1% lift.
Solution:
- Defaults work well: α = 1.0, λ = 1.0, ε = 0.1
- Focus on feature engineering, not hyperparameters
- Offline eval tells you if it matters
Key Takeaways
Essential concepts:
Offline evaluation is mandatory before production
- IPS (unbiased, high variance)
- Doubly Robust (best of both worlds, recommended)
- Validate on historical data with proper propensity scores
Production requires 8 core components:
- Context builder (feature extraction)
- Policy service (bandit algorithm)
- Event logger (comprehensive logging)
- Reward collector (delayed rewards)
- Offline evaluator (validate new policies)
- Policy trainer (batch updates)
- Monitor service (KPIs, alerts)
- Safety layer (circuit breaker, fallback)
Deploy gradually: staging → shadow → canary → full
- Shadow mode: Run in parallel, don’t impact users
- Canary: 5% → 10% → 20% → 50% → 100%
- Monitor closely at each stage
Logging is critical for success:
- Full context vector (all features)
- Propensity scores (for offline eval)
- Model metadata (version, hyperparams)
- Rewards (handle delayed attribution)
Monitor these KPIs:
- Performance: average reward, regret, policy value
- Exploration: action entropy, exploration rate
- System: latency (P99 <200ms), error rate (<1%)
Safety mechanisms prevent disasters:
- Circuit breaker (fallback after failures)
- Rate limiting (prevent runaway)
- Gradual rollout (detect issues early)
Production timeline:
- Weeks 1-2: Research & development
- Weeks 3-4: Offline evaluation
- Week 5: Staging deployment
- Weeks 6-7: Shadow mode
- Weeks 8-9: Canary deployment
- Week 10: Full rollout
Common failure modes:
| Problem | Symptom | Solution |
|---|---|---|
| Missing propensities | Can’t do offline eval | Log propensity with every decision |
| Delayed rewards | Underestimate performance | Implement reward collector with attribution |
| Stopped exploring | All traffic on one action | Monitor entropy, tune exploration |
| Distribution drift | Performance degrades | Retrain monthly, maintain small ε |
| No fallback | One failure breaks system | Circuit breaker + fallback policy |
Conclusion: You’re Ready for Production
You now have the complete production playbook:
✅ Offline evaluation to validate before deploying
✅ Production architecture with 8 core components
✅ Monitoring dashboard specification with KPIs
✅ Deployment workflow from research to production
✅ Pre-deployment checklist with 56 criteria
✅ Common pitfalls and how to avoid them
Next steps:
- Review your use case against Part 1 decision framework
- Implement algorithm from Part 3 (LinUCB or Thompson)
- Run offline evaluation using methods from this post
- Deploy gradually following the phased approach
- Monitor continuously using the dashboard specification
Remember: Start simple (LinUCB with α=1.0), validate thoroughly (offline eval), deploy gradually (canary), monitor closely (dashboard), and iterate (retrain monthly).
Contextual bandits are powerful, but production deployment requires rigor. Follow this guide, and you’ll deploy successfully.
Series Complete 🎉
This concludes the 5-part series on Contextual Bandits in Production.
The Complete Journey:
Part 1: When to Use Contextual Bandits
Decision framework, CB vs A/B vs MAB vs RL
Part 2: Mathematical Foundations
Regret bounds, exploration-exploitation, reward models
Part 3: Core Algorithms & Implementation
ε-greedy, UCB, LinUCB, Thompson Sampling with code
Part 4: Neural Contextual Bandits
Deep learning, uncertainty quantification, high-dim actions
Part 5: Production Deployment (this post)
Offline evaluation, architecture, monitoring, deployment
Further Reading
Production ML:
- Rules of Machine Learning - Google’s best practices
- Hidden Technical Debt in ML Systems - Sculley et al.
Offline Evaluation:
- Counterfactual Evaluation of Slate Recommendations - IPS for bandits
- Doubly Robust Policy Evaluation - Dudík et al.
Industry case studies:
- Netflix: Artwork Personalization via Bandits
- Spotify: Home Screen Recommendations
- LinkedIn: Feed Ranking
Tools:
- Vowpal Wabbit - Production bandit library
- Microsoft Decision Service - Cloud bandit platform
- Google Cloud AI Platform - Managed ML infrastructure
Questions? Feedback? Reach out on Twitter or LinkedIn
Want more? Subscribe for updates on advanced topics: non-stationary bandits, fairness constraints, multi-objective optimization.
Article series
Adaptive Optimization at Scale: Contextual Bandits from Theory to Production
- Part 1 When to Use Contextual Bandits: The Decision Framework
- Part 2 Contextual Bandit Theory: Regret Bounds and Exploration
- Part 3 Implementing Contextual Bandits: Complete Algorithm Guide
- Part 4 Neural Contextual Bandits for High-Dimensional Data
- Part 5 Deploying Contextual Bandits: Production Guide and Offline Evaluation