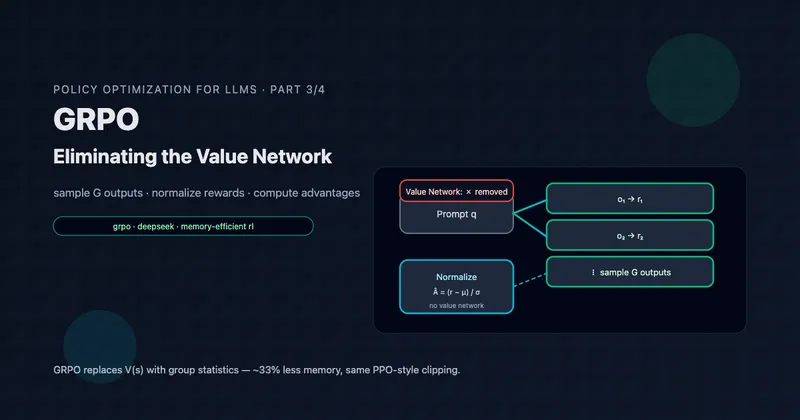
GRPO: Eliminating the Value Network
Group Relative Policy Optimization replaces PPO's learned value function with a simple insight: sample multiple outputs and use their relative rewards as advantages. 33% memory savings, simpler implementation, and the algorithm powering DeepSeek-R1.
Series
Read article Policy Optimization for LLMs: From Fundamentals to Production